What Is RAG and Why Your LLM Needs It (Part 1 of 3)
Learn what Retrieval-Augmented Generation is, why LLMs fail without it, and how the complete RAG pipeline works from ingestion to answer generation.
Estimated reading time: 8 minutes
Key Takeaways
- LLMs are smart but uninformed about your data: They reason well but know nothing about your documents, your products, or anything that happened after their training cutoff. RAG bridges that gap.
- RAG means "retrieve first, then generate": Instead of relying on memorized knowledge, the model reads relevant documents at query time and grounds its response in actual sources.
- The pipeline has two phases: Ingestion (load, chunk, embed, store) prepares your knowledge base. Retrieval + generation (embed query, search, assemble context, generate) answers questions.
- This is Part 1 of a 3-part series: This article covers the fundamentals. Part 2 dives into embeddings, vector databases, and chunking strategies. Part 3 covers 11 advanced RAG strategies for production systems.
Table of Contents
- The Problem With LLMs Nobody Talks About Enough
- What Is RAG and Why Should You Care?
- Why RAG Wins: Four Problems, One Architecture
- How RAG Actually Works: The Full Pipeline
- Frequently Asked Questions
- What's Next: The Foundation That Makes or Breaks RAG
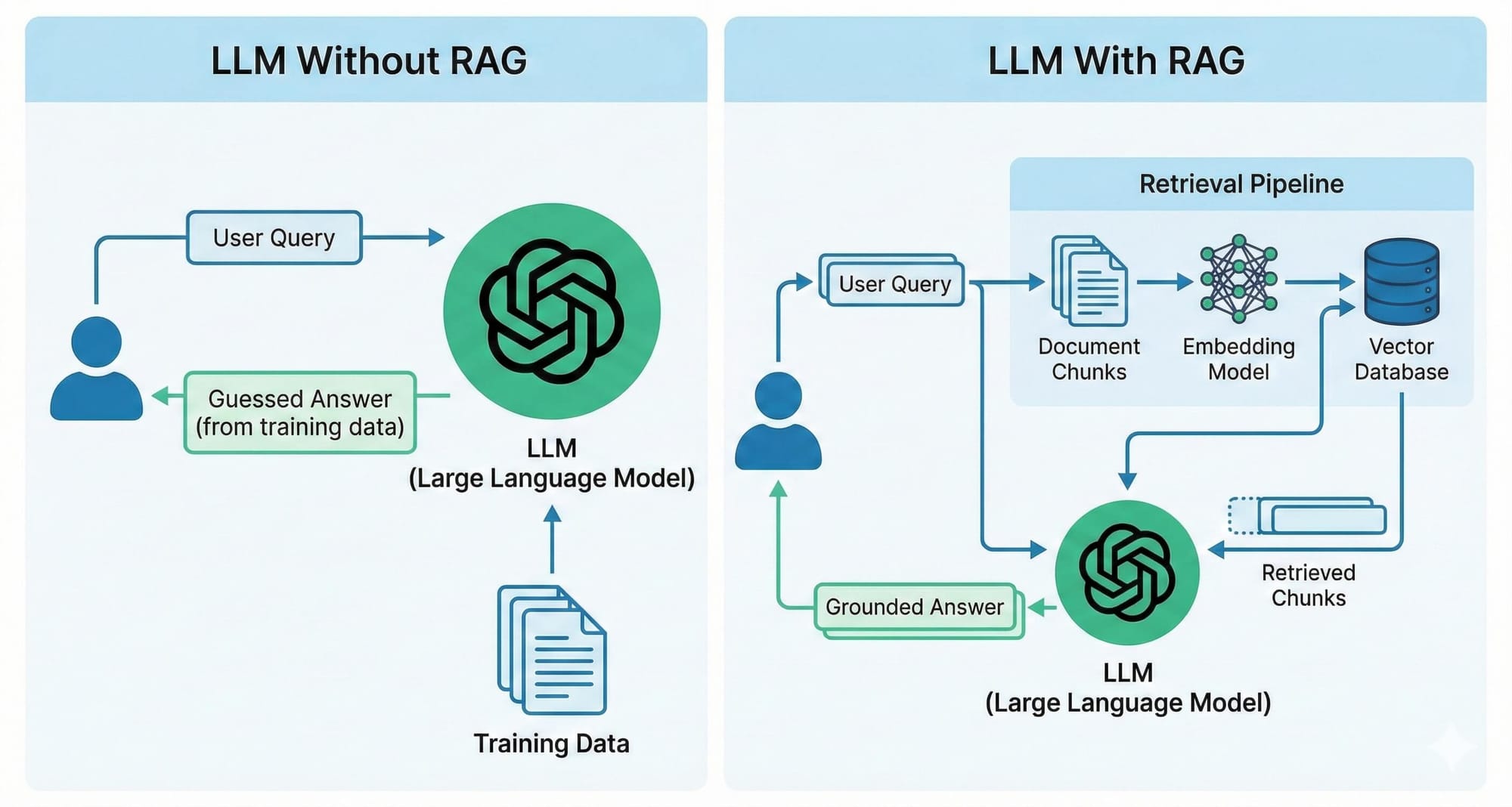
You've built something with an LLM. Maybe it's a chatbot, maybe it's an internal tool, maybe it's a document assistant for your team. It works, sort of. It can have a conversation. It sounds confident. But then someone asks it about your company's refund policy, or your product specifications, or a document that was uploaded last Tuesday and the model either makes something up or politely tells the user it doesn't have that information.
Here's the thing. Large Language Models are trained on vast amounts of public internet data. They know a lot about the world in general. But they know nothing about your data. Your internal documents, your knowledge base, your proprietary processes, none of that exists in the model's weights.
This is the fundamental tension at the heart of every LLM application: the model is brilliant at reasoning and language, but it's working from a fixed, generic knowledge base. It's like hiring a consultant who's incredibly smart but has never read a single document about your business.
There's a better way. It's called Retrieval-Augmented Generation — RAG — and it's become the standard architecture for building LLM applications that work with real, domain-specific data.
The Problem With LLMs Nobody Talks About Enough
Let's break this down to first principles. An LLM generates text by predicting the next token based on patterns it learned during training. It doesn't "know" facts, it has statistical associations between words and concepts. When you ask it a question, it generates the most likely response based on those patterns.
This works remarkably well for general knowledge, but it has three critical failure modes.
First, hallucinations. The model will confidently generate plausible-sounding text that's factually wrong. It's not lying, it's doing exactly what it was designed to do: produce likely text. But likely and correct are not the same thing.
Second, stale knowledge. Models have a training cutoff date. Anything that happened after that date doesn't exist in the model's world. For businesses where information changes daily, this is a non-starter.
Third, no access to private data. Your company's documents, your customer database, your internal wiki, the model has never seen any of it. It cannot answer questions about information it was never trained on, no matter how well you prompt it.
So how do you bridge that gap? You could fine-tune the model on your data, but that's expensive, slow, and needs to be repeated every time your data changes. You could stuff everything into the prompt, but context windows have limits and that approach doesn't scale past a handful of documents.
Ask yourself: is there a way to give the model the right information at the right time, without retraining it?
That's exactly what RAG does.
What Is RAG and Why Should You Care?
RAG — Retrieval-Augmented Generation — is an architecture pattern that gives LLMs access to external knowledge at query time. Instead of relying only on what the model learned during training, RAG retrieves relevant information from your data sources and includes it in the prompt before the model generates a response.
The concept was introduced in a 2020 research paper by Patrick Lewis and colleagues at Facebook AI Research (now Meta AI). The idea was straightforward: combine a retrieval system (think search engine) with a generative model (the LLM) so that the model's responses are grounded in actual source documents.
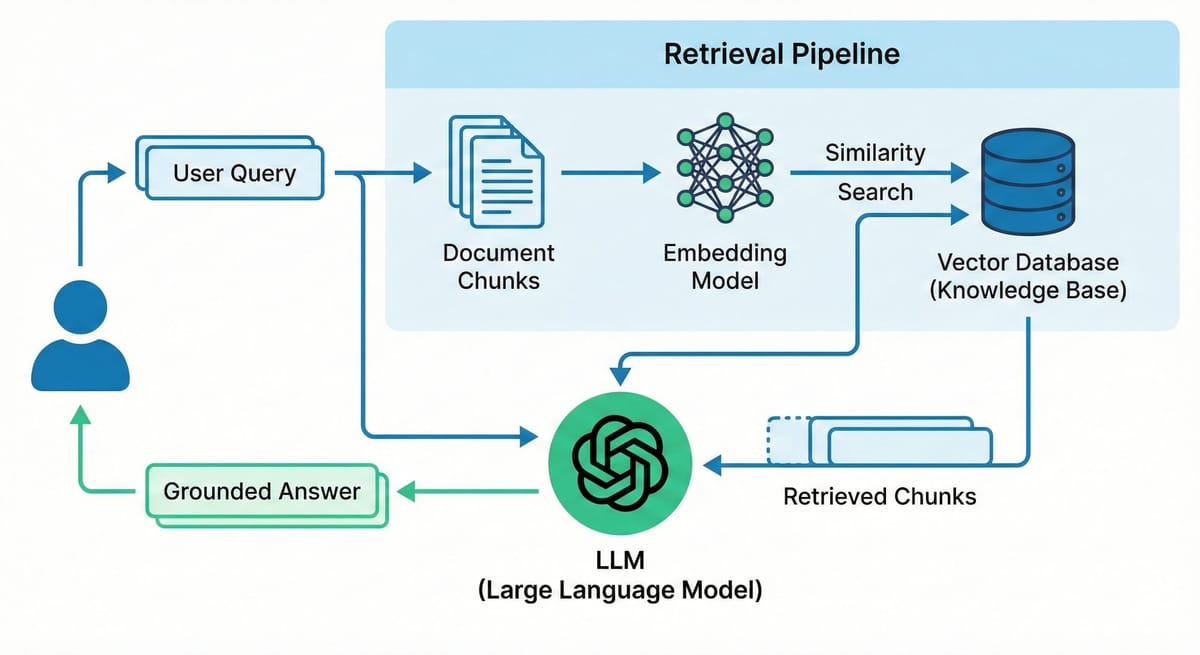
Here's how this actually works in plain terms. A user asks a question. Before the LLM sees that question, the system searches your knowledge base for the most relevant documents. Those documents get attached to the prompt. The LLM reads them and generates a response based on what it just read, not what it memorized during training.
The model doesn't need to know the answer. It just needs to read the relevant documents and reason about them. This is the same thing a human expert does. Nobody memorizes everything. The skill is knowing where to look and how to interpret what you find.
Think of it this way: asking a vanilla LLM a domain-specific question is like giving someone a closed-book exam on material they've never studied. RAG turns that into an open-book exam. The model still does the reasoning, that's what it's good at, but now it has the right reference materials in front of it.
Why RAG Wins: Four Problems, One Architecture
RAG solves the three failure modes I mentioned, and a fourth one that matters just as much in practice.
The hallucination problem. With RAG, the model's response is grounded in actual documents. You can trace every claim back to a source. When the model says your refund window is 30 days, it's because it just read your refund policy document, not because "30 days" is a statistically common answer.
The freshness problem. RAG systems pull data at query time. Update the document in your knowledge base, and the next query gets the updated information. No retraining. No waiting. The system is as current as your latest document.
The domain expertise problem. RAG lets you build domain expertise without touching the model itself. Your knowledge base becomes the model's specialized knowledge and you control exactly what goes in there. Whether that's healthcare compliance, financial regulations, or internal company processes.
The cost problem. Fine-tuning large models requires GPUs, training data, evaluation pipelines, and ongoing maintenance. RAG sidesteps most of that cost. You run an embedding model once during ingestion (relatively cheap), store vectors in a database, and use the LLM only at query time for generation. For most organizations, this is orders of magnitude cheaper than fine-tuning.
How RAG Actually Works: The Full Pipeline
A RAG system has two distinct phases: ingestion (preparing your data) and retrieval + generation (answering queries). Let's walk through both.
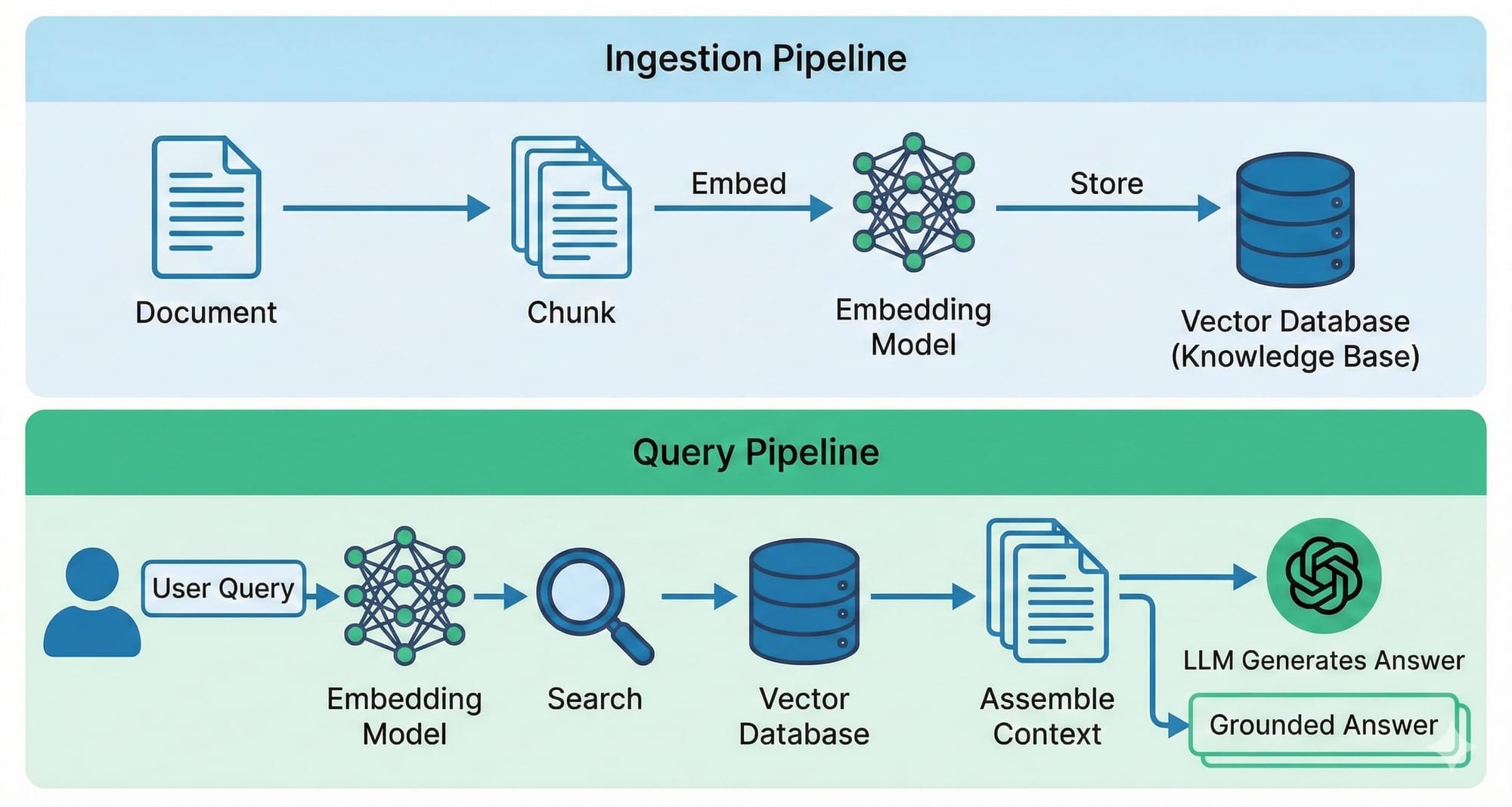
Phase 1: Ingestion — Preparing Your Knowledge Base
Before your RAG system can answer questions, it needs to process and store your documents. This happens once per document (or when documents are updated).
1. Document Loading. Your documents come in many formats, PDFs, Word files, HTML pages, markdown. The first step is converting everything into raw text. Tools like Docling, Unstructured, or LangChain's document loaders handle this. The quality of your text extraction matters more than most people realize — garbage in, garbage out applies here in full force.
2. Chunking. Raw documents are too large to work with directly. A 50-page PDF doesn't fit in an embedding model's context window, and even if it did, the resulting embedding would be too generic to match specific queries. So you split documents into smaller pieces, chunks. This is one of the most consequential decisions in your entire pipeline, and I'll cover it in depth in Part 2.
3. Embedding. Each chunk gets converted into a numerical vector — a list of numbers that captures the meaning of that text. Similar meanings produce similar vectors, regardless of the exact words used. This is what makes semantic search possible. More on this in Part 2 as well.
4. Storing. The embeddings (along with the original text and metadata) get stored in a vector database, a database optimized for finding the most similar vectors as fast as possible. Think of it as a search engine that understands meaning, not just keywords.
Phase 2: Retrieval + Generation — Answering Queries
When a user asks a question, here's what happens:
1. Query Embedding. The user's question gets converted into a vector using the same embedding model that processed the documents. This is critical, the query and the documents must live in the same vector space for similarity comparisons to work.
2. Retrieval. The system searches the vector database for the chunks whose embeddings are most similar to the query embedding. Typically, you retrieve the top 3-10 most relevant chunks using cosine similarity as the distance metric.
3. Context Assembly. The retrieved chunks are formatted and assembled into a context block that gets inserted into the LLM's prompt alongside the user's query. The prompt essentially says: "Here are some relevant documents. Based on these documents, answer the following question."
4. Generation. The LLM reads the context and generates a response grounded in the retrieved information. A well-designed system also includes the source references so the user can verify the answer.
That's the core pipeline. Four steps in, four steps out. Everything else — and there's a lot of "everything else", is about making each step better.
Frequently Asked Questions
What's the difference between RAG and fine-tuning?
RAG gives the model access to information at query time, like giving someone a reference book. Fine-tuning changes the model's weights, like teaching someone new knowledge permanently. Use RAG when your data changes frequently or you need source attribution. Use fine-tuning when you need the model to behave differently (tone, format, reasoning). Many production systems use both.
Can I use RAG with open-source LLMs?
Absolutely. RAG is architecture-agnostic, the retrieval pipeline is independent of which LLM does the generation. You can use Llama, Mistral, or any other model. Running everything on your own infrastructure is the most privacy-preserving setup possible.If you're not sure where to start, my guide to self-hosting LLMs with Ollama covers the full setup.
How much data do I need for RAG to be useful?
There's no minimum. RAG works with a single document. Even a modest collection of 50-100 documents can produce significantly better results than a bare LLM for domain-specific questions.
Is my data safe in a RAG system?
This depends on your architecture choices. Cloud embedding APIs send your text to external servers. Local embedding models keep data on your infrastructure. Treat your embeddings with the same security posture as your source documents, they can be used to approximately reconstruct the original text.
How do I handle documents that are updated frequently?
Re-ingest them. Delete old chunks and embeddings, re-chunk the new version, re-embed, and store. For frequently changing documents, automate this pipeline. The key is that your knowledge base always reflects the current version.
What's Next: The Foundation That Makes or Breaks RAG
The pipeline I've described is the skeleton of every RAG system. But the quality of your results depends almost entirely on three foundational choices: how you create embeddings, where you store them, and how you split your documents into chunks.
Get any one of these wrong, and no amount of clever prompting or model selection will save you. Get them right, and you have a system that can genuinely transform how your team works with information.
In Part 2, I'll take you deep into these three pillars, embeddings (how they work, which models to choose, and the similarity metrics that compare them), vector databases (the six major options and when to use each), and chunking strategies (seven different approaches with the trade-offs that matter). These are the decisions that separate a RAG demo from a RAG system that actually works.
The foundation determines everything. Let's get it right.
P.S. This is Part 1 of a 3-part series on RAG.
Continue to Part 2: Embeddings, Vector Databases, and Chunking Strategies for the deep dive into RAG's foundational building blocks. Read The Part 2
Continue to Part 3: 11 Advanced RAG Strategies That Separate Demos From Production Systems. Read The Part 3
Don't miss out on future posts and exclusive content—subscribe to my free newsletter today.
Ready to connect or explore more? Head over to my LinkedIn profile