The Ultimate Guide to AI for Sysadmins and Developers (Part 1): From Neural Networks to the MLOps Factory Floor
Tired of treating AI like a magic black box? This practical guide for sysadmins and developers demystifies neural networks and the MLOps lifecycle. Learn to build, scale, and manage the engineering backbone of modern AI. Part 1 of our ultimate guide.

Estimated reading time: 12 minutes
Key Takeaways
- AI is a Hierarchy: Artificial Intelligence (AI) is the broad concept of mimicking human intelligence. Machine Learning (ML) is a subset of AI that learns from data, and Deep Learning is a specialized type of ML using multi-layered neural networks to find complex patterns.
- Neural Networks as Engineering Systems: A neural network isn't magic; it's a complex mathematical function. Viewing it as a factory assembly line—with an input layer (raw materials), hidden layers (workstations), and an output layer (finished product)—demystifies how it works.
- MLOps is Critical for Production AI: Machine Learning Operations (MLOps) applies DevOps principles to the AI lifecycle but differs critically because it manages both code and data. Models decay over time (model drift), requiring continuous monitoring and retraining.
- Hardware and Software Stack Matters: AI infrastructure is specialized. Training requires high-throughput hardware (like NVIDIA H200) to process massive datasets, while inference needs low-latency hardware (like NVIDIA T4) for fast predictions. Docker and Kubernetes are essential tools for creating reproducible and scalable AI deployments.
Table of Content
- Demystifying the "Brain": An Engineer's Guide to Neural Networks
- The AI Factory: MLOps and the Infrastructure of Intelligence
- What's Next on the Assembly Line?
So, you're a sysadmin, DevOps practitioner, or developer? You've probably noticed that "Artificial Intelligence" has gone from a sci-fi buzzword to something that's actually sitting in your IDE right now. It's in your monitoring tools, your deployment pipelines, and honestly? It's getting hard to avoid.
But here's the thing: what is it, really? How does it actually work under the hood? And more importantly, how can those of us who build and maintain systems actually harness it without feeling like we're fumbling in the dark?
This is Part 1 of a two-part guide designed to demystify AI from a systems and engineering perspective. To really build with, secure, and scale AI, we can't treat it like a magic black box. We need to understand the engine. In this article, we'll dive deep into how neural networks actually work and explore the infrastructure needed to bring AI to life through MLOps.
In Part 2, we'll tackle the strategic decision of open-source versus proprietary models and get hands-on with practical tools you can start using today. First things first, let's pop the hood and see what's really going on.
Demystifying the "Brain": An Engineer's Guide to Neural Networks
To effectively manage and deploy AI systems, you need to understand what's happening beneath the surface. Let's break down the core concepts and move past the "magic" to reveal the actual mechanics.
From AI to Deep Learning: A No-Nonsense Hierarchy
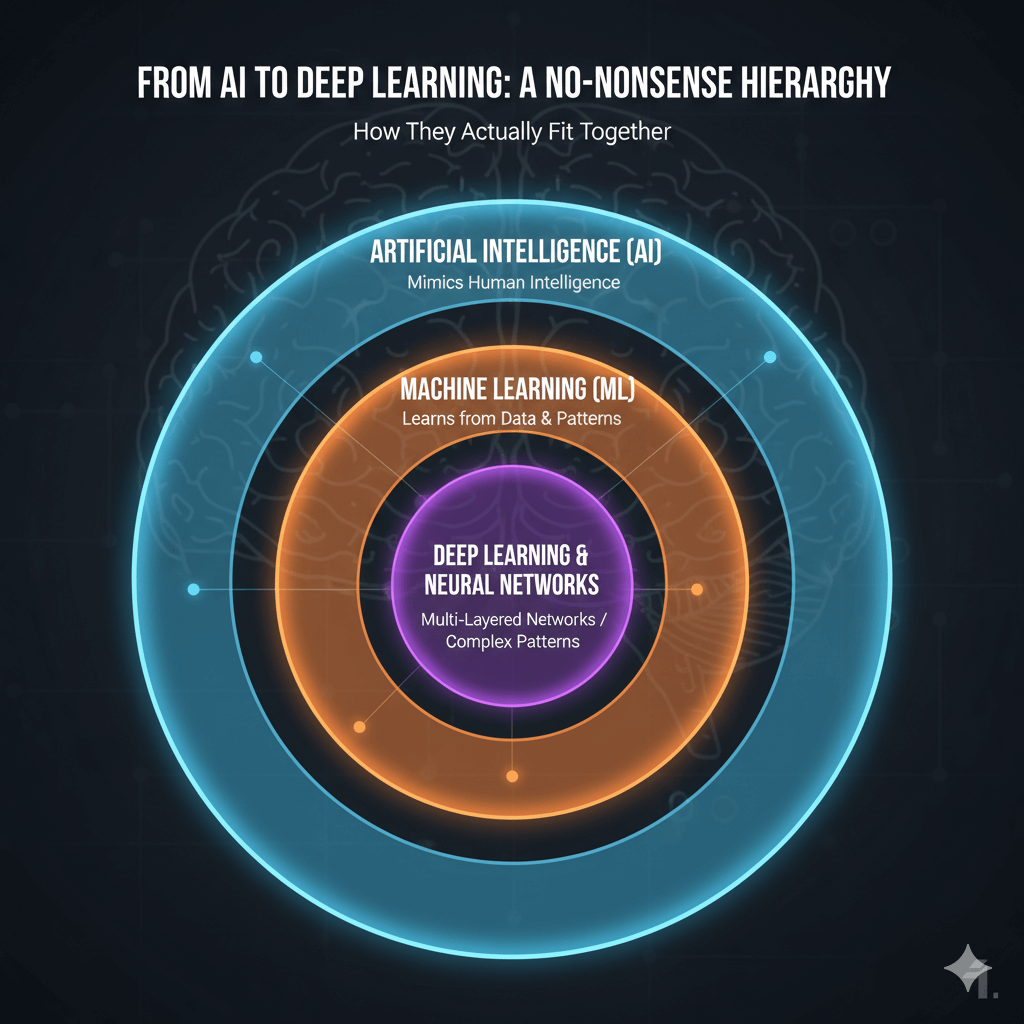
People throw around AI, Machine Learning, and Deep Learning like they're interchangeable. They're not. Here's how they actually fit together:
- Artificial Intelligence (AI): This is the broadest umbrella term for any technique that enables computers to mimic human intelligence. The goal is to create systems that can reason, learn, and solve problems.
- Machine Learning (ML): A subset of AI, ML involves methods that allow systems to learn patterns directly from data without being explicitly programmed. For instance, instead of writing thousands of complex if/else statements to identify a spam email (a nightmare for any developer), an ML model is shown tens of thousands of examples of spam and non-spam emails. It learns the characteristics that differentiate the two, effectively writing its own rules.
- Deep Learning & Neural Networks: This is a specialized and powerful type of ML that uses multi-layered structures called Artificial Neural Networks (ANNs). Inspired by the brain, these networks excel at learning intricate patterns from vast amounts of data. Deep learning is the engine behind most of the recent breakthroughs, from facial recognition to large language models.
Inside the Neural Network: A View from the Factory Floor
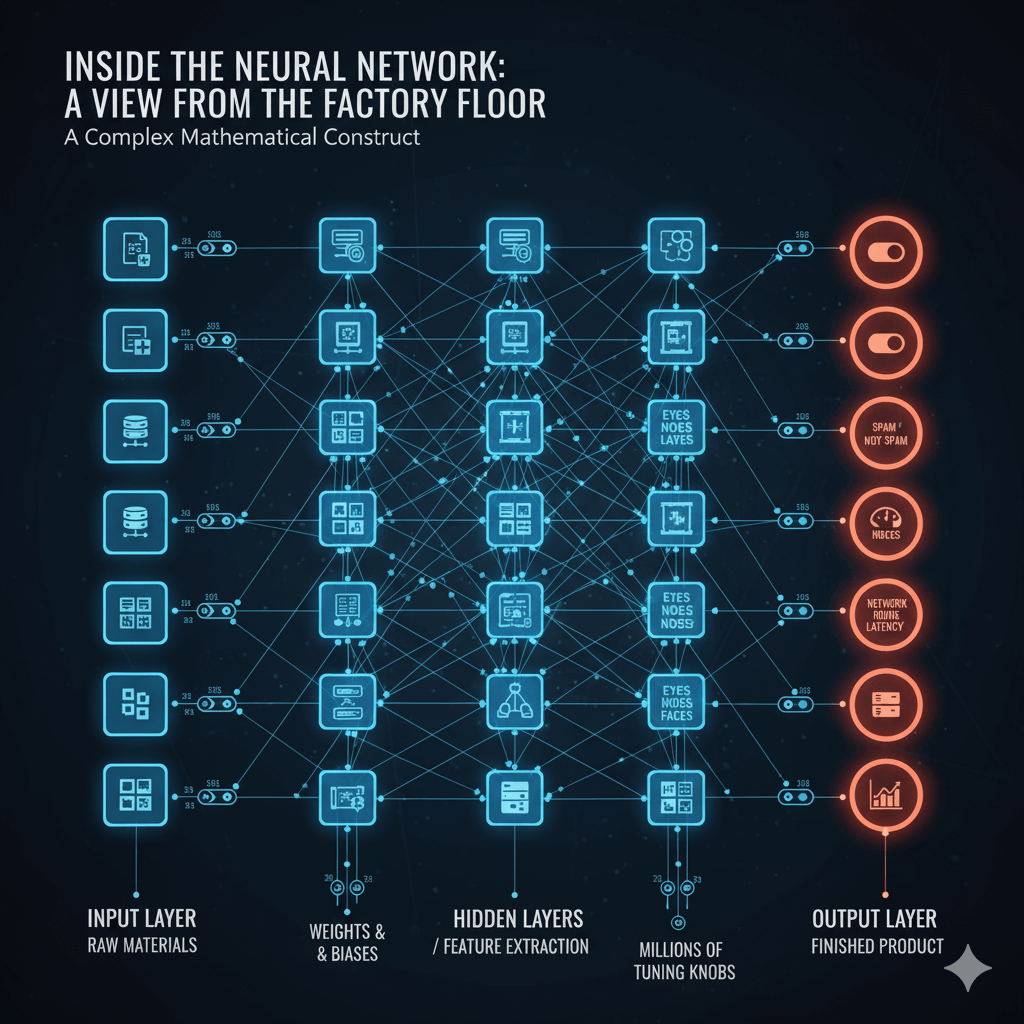
While the biological brain provides a useful starting point, I've found it's a poor technical model for an engineer. A more practical and accurate view is to see a neural network as a complex mathematical construct—an engineering system. At its core, a neural network is just a massive, composite mathematical function that maps an input to a predicted output.
Each "neuron" is a smaller function. It takes inputs, multiplies them by weights, adds a bias, and passes the result through an activation function. Think of it as a factory assembly line.
- Input Layer: This is where the raw materials enter. For you, these inputs could be lines from a log file, server performance metrics, network packet data, or the pixels of an image.
- Hidden Layers: These are the workstations. Each hidden layer receives the output from the previous one and performs a transformation, extracting progressively more abstract features. In an image recognition task, the first layer might spot simple things like edges and colors. The next might combine those to see shapes or textures. Deeper layers might recognize objects like eyes or a nose, eventually assembling them into a complete face. A network with two or more hidden layers is what makes it "deep".
- Output Layer: This is the final station where the finished product is delivered. The output could be a classification ("spam" or "not spam"), a probability (a 95% chance of server failure), or a continuous value (predicted network latency).
And the connections between these neurons aren't all equal. Each has a weight, representing its importance. Think of these weights and their associated biases as millions of tiny tuning knobs on the factory's machinery. The entire "learning" process is just an automated search for the perfect settings for all these knobs.
The Learning Loop: How the Machine Gets Smart
So, how does the network find the right settings for those millions of knobs? It learns by iteratively adjusting them to minimize its errors, powered by a feedback loop.
The Goal: Minimizing Error with a Loss Function
The objective of training is to make the model's prediction as close as possible to the actual truth. The gap between the prediction and the truth is measured by a loss function. A great analogy for this is learning archery. The bullseye is the correct answer, and your arrow's landing spot is the model's prediction. The loss is the distance between the arrow and the bullseye. Your goal is to adjust your aim (the weights and biases) to minimize this distance with each shot.
The Method: Gradient Descent, or Finding the Way Downhill
This is the core optimization algorithm used to minimize that loss. Imagine you're stuck on a vast, hilly landscape in dense fog, and your goal is to reach the lowest point in the valley (the minimum loss). You can't see the path. All you know is the slope of the ground right where you're standing. What do you do? You feel for the steepest downward direction (this is the gradient) and take a step. By repeating this process, you gradually descend into the valley. In neural network training, each "step" is a small adjustment of the model's weights and biases in the direction that most effectively reduces the loss.
The Feedback: Backpropagation
This is the mechanism (a machine learning algorithm essential) that makes the whole thing work. After the model makes a prediction and the loss is calculated, the error is propagated backward through the network. Think of it this way: after you shoot your arrow in archery and miss, backpropagation is the process that tells you not just that you missed, but how your stance, arm position, and release each contributed to the error. It uses calculus (specifically, the chain rule) to determine how much each individual "tuning knob" contributed to the total error. This information—the gradient—is then used by gradient descent to make the right adjustments for the next shot.
Key Insight for Builders & A Look Ahead
The big takeaway here is that a neural network isn't magic. It's a highly complex, but ultimately understandable, function approximator. As a sysadmin or developer, you're already familiar with functions, inputs, outputs, and algorithms. Framing neural networks in these terms demystifies the process and turns it into an engineering problem.
And this machinery is constantly evolving. The "workstations" on the assembly line are being upgraded with new architectures like Transformers, which are breaking out of just language processing; Graph Neural Networks (GNNs), which excel at understanding interconnected data; and Hybrid AI, which combines rule-based logic with adaptive learning.
The AI Factory: MLOps and the Infrastructure of Intelligence
Understanding the theory is the first step. The next is to appreciate the industrial-scale process required to build, deploy, and maintain these models in production. This is the world of Machine Learning Operations (MLOps).
Why MLOps Isn't Just "DevOps for ML"
MLOps applies DevOps principles to the unique challenges of the AI lifecycle. But what I find fascinating is where the two disciplines diverge. In traditional DevOps, the "source of truth" is code in a Git repo, and the artifact is a compiled binary or container image. That artifact is immutable. In MLOps, the "source of truth" is both code and data. This is a huge deal. The artifact—the model—is not immutable; its performance decays over time as the real world changes. This is called model drift. This transforms the operational challenge from managing a code pipeline to managing a living, data-driven system that requires constant validation against reality.
And this isn't some niche corner of the industry. The MLOps market is set to explode from around $2.3 billion in 2025 to nearly $20 billion by 2032. This isn't a fad; it's the foundation of production AI. It's no surprise that 97% of users who implement MLOps report significant improvements in automation, productivity, and robustness.
The MLOps Lifecycle: From Idea to Production and Back Again
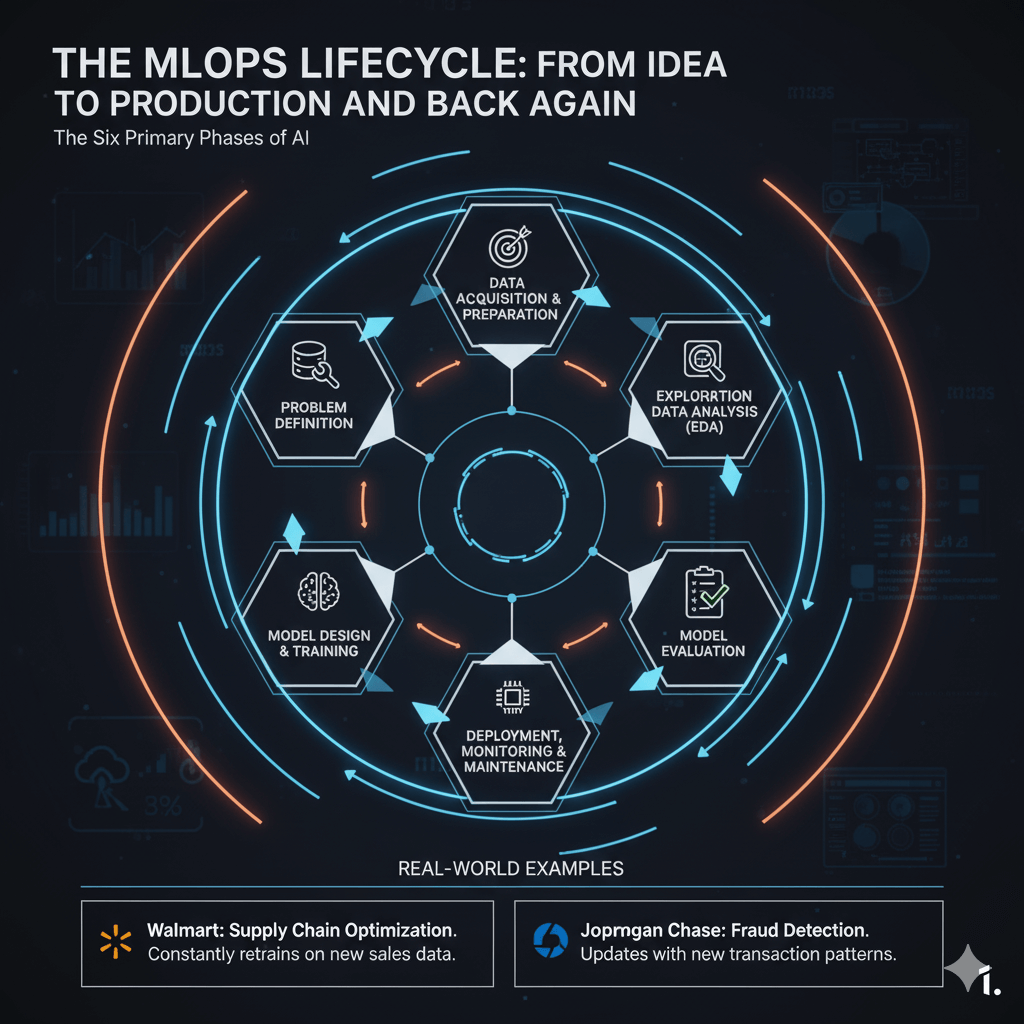
The AI lifecycle can be broken down into six primary phases:
- Problem Definition: Clearly defining the business objective and success metrics. Without this, you're just playing with expensive toys.
- Data Acquisition & Preparation: Data is the fuel. This phase involves gathering, cleaning, and transforming data. Fair warning: this is often the most time-consuming stage. If your data is garbage, your model will be garbage.
- Exploratory Data Analysis (EDA): Analyzing the data to understand its patterns and uncover potential biases before you start training.
- Model Design & Training: Selecting an architecture and training the model on the prepared dataset. This is the computationally intensive part.
- Model Evaluation: Rigorously testing the model on unseen data to ensure it can generalize and isn't just "memorizing" the training examples. This is your reality check.
- Deployment, Monitoring & Maintenance: Integrating the model into production. But the job isn't done. You must continuously monitor for model drift and have a feedback loop for retraining and redeployment.
To make this tangible, look at real-world examples. Walmart uses MLOps to manage its supply chain models, constantly retraining them on new sales data to optimize inventory. JPMorgan Chase uses it to keep their fraud detection models ahead of attackers by feeding them new transaction patterns. This shows just how critical that final monitoring and retraining loop is.
The Hardware Layer: A Sysadmin's Cheat Sheet
AI infrastructure is not one-size-fits-all. The hardware you need is dictated by whether you're training a model or using it for inference. Training is the process of teaching the model by feeding it massive datasets. It's a computationally brutal, highly parallel workload. The goal is to optimize for throughput—processing as much data as possible. Inference is the process of using the trained model to make a prediction on new data. This needs to happen fast, often in real-time. The goal is to optimize for latency—delivering a single result as quickly as possible.
Getting this distinction wrong is one of the most common—and costly—mistakes I see people make. It's like using a massive data warehousing server to handle a high-traffic API. You need the right tool for the job.
| Component | Training (Optimize for Throughput) | Inference (Optimize for Latency) |
|---|---|---|
| The Job | Training the model on massive datasets — a long, highly parallel process. | Using the trained model for predictions — a fast, real-time operation. |
| Example GPUs / TPUs |
NVIDIA H200 / H100 SXM: Built for massive parallel computing and raw throughput. Google Ironwood TPU: Optimized for large-scale distributed training. |
NVIDIA T4 / A10 / L40: Cost-efficient, power-optimized GPUs ideal for serving models. |
| RAM | Large memory (≥128 GB) to handle datasets and parallel GPU processes. | Moderate memory (16 – 64 GB) sufficient for model loading and requests. |
| Storage | Ultra-fast NVMe SSDs to prevent I/O bottlenecks during data loading. | High-speed NVMe SSDs for quick model access and initialization. |
These specs have real-world consequences. For instance, the NVIDIA H200 SXM's massive 141 GB of HBM3e memory is a game-changer because it allows huge models to be trained entirely in-GPU memory, slashing training times by avoiding slow data transfers. On the other side, Google's Ironwood TPU is their first chip designed specifically for inference, signaling a major industry shift where the cost and efficiency of using models is becoming just as important as training them.
The Modern AI Stack: Containers, Kubernetes, and AI Building AI
Now let's talk about the software stack that runs on top of that hardware.
Containerizing Intelligence: Docker for Reproducibility
The "it works on my machine" problem is a nightmare in ML. A model might depend on a specific version of PyTorch, a certain CUDA driver, and a dozen other libraries. Docker solves this by packaging the model, its code, and all its dependencies into a portable, consistent container image. This is the foundation of sane MLOps. When a data scientist hands you a container image, you know it'll run the same way in production as it did on their laptop.
Orchestrating at Scale: Why Kubernetes is King
In production, AI services need to be highly available and scale on demand. Kubernetes has become the de facto standard for orchestrating these containerized AI applications. The numbers back this up: a 2025 survey shows that 90% of organizations expect their AI workloads on Kubernetes to grow, and cost has now become their number one challenge.
But here's the catch: the very tool we use to manage complexity—Kubernetes—can become overwhelmingly complex itself. With thousands of pods generating millions of alerts, how do you find the signal in the noise? This is where AIOps comes in. It's about using AI to manage IT operations. One case study I saw was particularly compelling. By implementing AI-driven monitoring for their Kubernetes environment, a team was able to reduce alert noise by 60% and achieve 40% faster incident resolution. They went from being buried in low-priority notifications to focusing only on what was critical. That's a concrete result that speaks directly to any operator's goals.
When AI Helps Build AI: A Glimpse into the Future
What's really exciting is that AI is now starting to influence the DevOps workflow itself. We're seeing the rise of AI-powered tools that can generate Dockerfiles and Kubernetes manifests from natural language prompts. You can describe your stack—"Create a Dockerfile for a Node.js application that uses npm"—and the AI can produce a solid starting point.
But this trend comes with a critical caveat. These tools are powerful accelerators, but they require careful human oversight. The Stack Overflow 2025 Developer Survey found that more developers distrust the accuracy of AI tools than trust them (46% vs. 33%). The single biggest frustration, cited by 66% of developers, is dealing with "AI solutions that are almost right, but not quite". This grounds the hype in reality. AI isn't replacing the DevOps engineer. It's becoming a powerful junior assistant. It can draft the boilerplate, but an expert still needs to review the output for security, efficiency (like using multi-stage builds), and correctness. It's a tool, not a replacement.
What's Next on the Assembly Line?
Okay, so now you've got the lay of the land. You see the assembly line, you understand the machinery, and you know why the factory floor needs a whole new set of rules. This is the essential foundation. But the real fun begins when you have to start making choices.

In Part 2, we'll tackle the strategic questions you're probably already thinking about:
- Open-source vs. proprietary models: Should you build on open-source models like Llama 3 or pay for proprietary APIs like GPT-4o? We'll break down the cost, control, and performance trade-offs.
- The self-hosting decision: What are the real infrastructure costs and operational burdens of running your own LLM?
- Practical applications: How can you start using AI in your daily workflow today for scripting, debugging, and log analysis?
- Hands-on tutorial: We'll walk through setting up your first self-hosted LLM with Ollama in just a few commands—your "Hello, World!" for local AI.
Don't miss out on future posts and exclusive content—subscribe to my newsletter today.
Ready to connect or explore more? Head over to stratoslouvaris.gr