11 Advanced RAG Strategies That Separate Demos From Production Systems (Part 3 of 3)
Basic RAG works for demos, but production demands more. Explore 11 advanced strategies, from re-ranking and multi-query to agentic and self-reflective RAG, that solve specific failure modes. Learn how to stack these techniques to build accurate, production-ready AI systems.
Estimated reading time: 8 minutes
Key Takeaways
- Each strategy solves a specific problem: Re-ranking improves precision, multi-query improves recall, contextual retrieval fixes chunk context loss, and self-reflective RAG self-corrects when results are poor. Pick the strategy that matches your failure mode.
- Strategies stack — and they should: Production RAG systems combine multiple strategies. The right combination depends on your accuracy requirements, latency budget, and cost tolerance.
- Not every system needs every strategy: A customer support chatbot and a medical research tool have fundamentally different requirements. Match the investment to the stakes.
- This is Part 3 of a 3-part series: Part 1 covered what RAG is. Part 2 covered embeddings, vector databases, and chunking. This article covers the 11 strategies and how to combine them.
Table of Contents
- The 11 Strategies: What They Are and When to Use Them
- Combining Strategies: Four Production Stacks
- Frequently Asked Questions
- Build It, Measure It, Improve It
In Part 1 and Part 2, I covered the fundamentals — what RAG is, how the pipeline works, and the three foundational pillars (embeddings, vector databases, chunking). If you've followed along, you have a solid understanding of the mechanics.
But here's where it gets real. A basic RAG pipeline — embed, search, retrieve, generate — works for demos. In production, it runs into problems. Queries are vague. Retrieved chunks are irrelevant. The LLM generates confident answers from poor context. Users notice.
The 11 strategies I'm about to walk through each solve a specific failure mode. Some improve what happens during ingestion. Others improve retrieval at query time. A few add intelligence loops that make the system self-correcting. Understanding what each one does — and when to reach for it — is what separates a working system from a frustrating one.
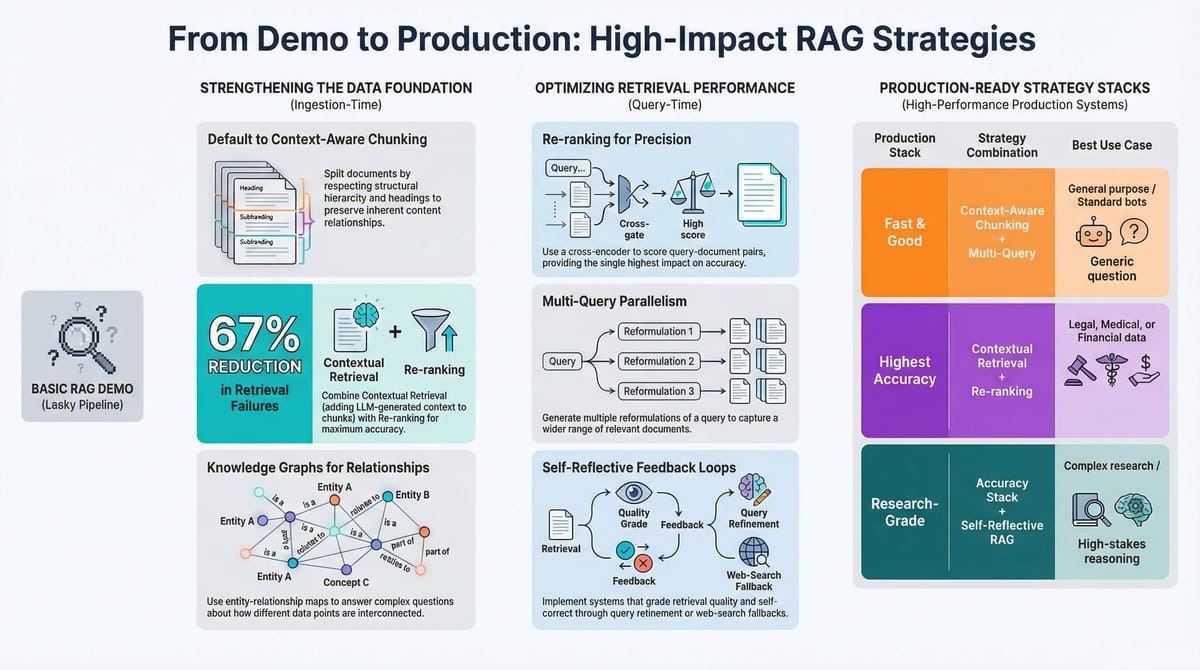
The 11 Strategies: What They Are and When to Use Them
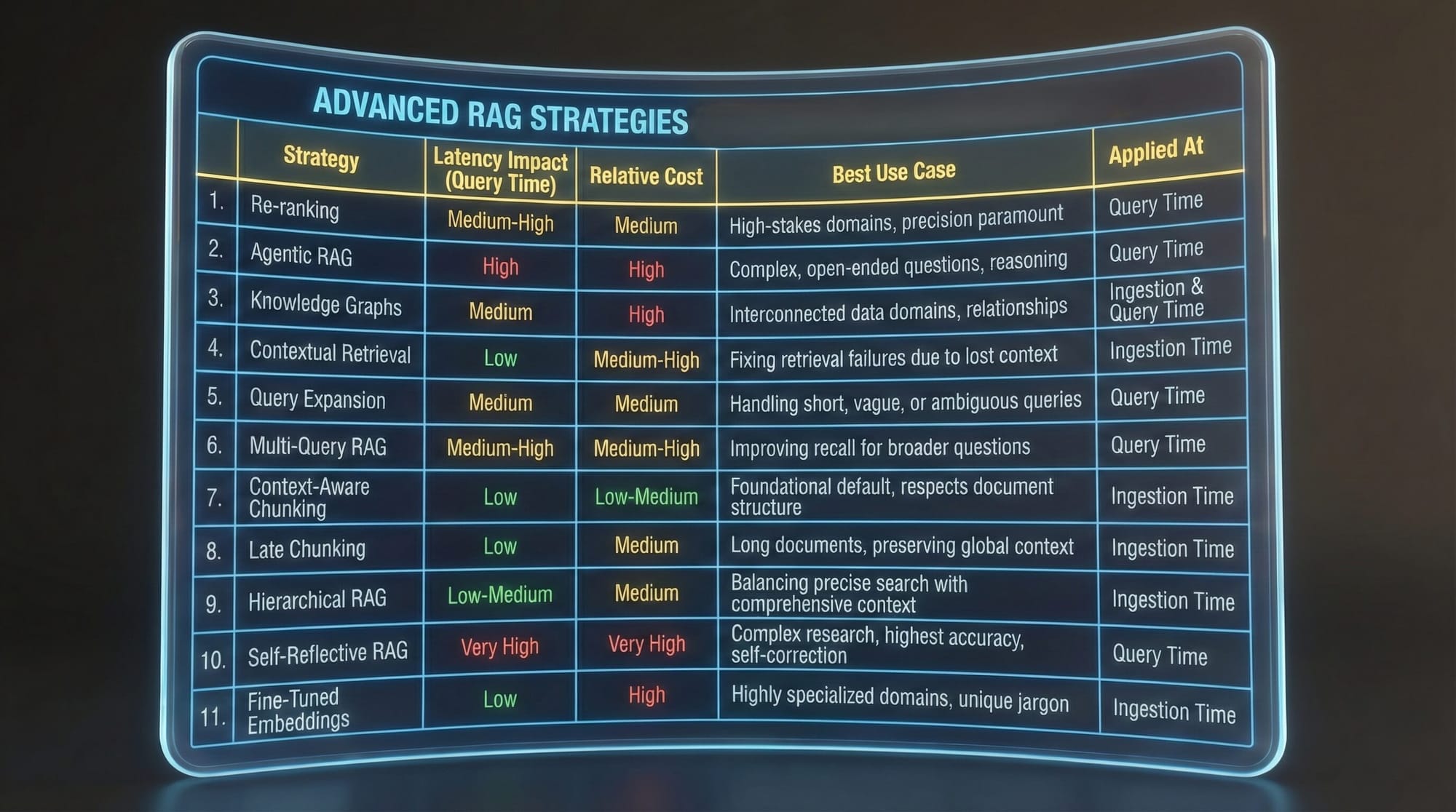
1. Re-ranking (Two-Stage Retrieval)
Standard vector search retrieves the top N chunks by embedding similarity. Re-ranking adds a second stage: retrieve 20 candidates fast, then use a cross-encoder model to score each query-document pair together. The cross-encoder reads the query and document side by side, understanding nuances that separate embeddings miss. This is the single most impactful addition to a basic pipeline when precision matters — legal, medical, financial queries. Adds latency but dramatically improves accuracy.
2. Agentic RAG (Multi-Tool Retrieval)
Instead of a rigid pipeline, an AI agent gets multiple retrieval tools and decides which to use per query. Semantic search, full-document retrieval, re-ranking, multi-query — all available as options the agent selects based on query analysis. When a user asks "What's our complete refund policy?", the agent might start with semantic search, find incomplete chunks, then pull the full document. Maximum flexibility, but harder to debug and less predictable.
3. Knowledge Graphs (Graph RAG)
Vector search finds similar text. But some questions are about relationships: "Who is the CEO of ACME Corp?" Knowledge graphs store explicit entity-relationship facts (ACME Corp → has CEO → Jane Smith) and combine graph traversal with vector search. Excellent for interconnected data — healthcare, finance, research — but requires significant infrastructure (typically Neo4j), an entity extraction pipeline, and ongoing schema maintenance.
4. Contextual Retrieval (The Anthropic Method)
When you chunk a document, each chunk loses its broader context. A chunk saying "Clean data is essential. Remove duplicates..." doesn't tell you whether it's about data science or database administration. Contextual retrieval fixes this at ingestion: for every chunk, an LLM generates 1-2 sentences explaining what the chunk discusses relative to the full document. That context gets prepended before embedding. Anthropic's benchmarks show a 35-49% reduction in retrieval failures, and 67% when combined with re-ranking. The catch: one LLM API call per chunk during ingestion.
5. Query Expansion
Short or vague queries produce generic embeddings. Query expansion uses an LLM to enrich the query — adding context, related terms, and alternative phrasings while preserving intent. "What is RAG?" might expand to "What is Retrieval-Augmented Generation, how does it work, and what are its main components?" Handles vague queries well. One LLM call. Works best as a building block for multi-query RAG.
6. Multi-Query RAG
Takes query expansion further by generating multiple different reformulations of the original query, running all of them in parallel against the vector database, and deduplicating the combined results. Four parallel searches capture far more relevant documents than any single search. Significantly better recall. The parallel execution keeps latency reasonable despite the extra database load.
7. Context-Aware Chunking
I covered chunking strategies in Part 2, but context-aware chunking deserves its own mention as a strategy. Using tools like Docling's HybridChunker, you split documents respecting structure, token limits, and heading hierarchy. Each chunk carries context about where it sits in the document. Fast, free, and should be your default for all ingestion. The foundation that makes every other strategy work better.
8. Late Chunking
Standard chunking embeds each chunk independently — each chunk only "knows" its own content. Late chunking flips the process: embed the entire document through the transformer first, then chunk the resulting token embeddings. Each chunk's vector carries information from the whole document because the attention mechanism mixed context across all tokens before chunking. Powerful for long documents, but requires embedding models with large context windows (8K+ tokens) and isn't widely supported yet.
9. Hierarchical RAG (Parent-Child)
Addresses the chunk size dilemma directly: store small child chunks for precise search and large parent chunks for rich context. Search finds the precise child match, but the LLM receives the parent chunk. A query about "Q2 revenue" matches a small chunk with the specific number, but the LLM gets the entire Q2 report section for comprehensive reasoning. Best of both worlds, but requires a parent-child schema.
10. Self-Reflective RAG (Self-RAG / CRAG)
Adds a feedback loop: after retrieval, an LLM grades the relevance of retrieved documents (1-5 scale). If the grade is below threshold, the system generates a refined query and searches again. Self-correcting. Two major variations — Self-RAG grades both retrieval and generation quality; Corrective RAG (CRAG) falls back to web search when local retrieval fails. Best accuracy for complex research queries, but highest latency and cost (multiple LLM calls per query).
11. Fine-Tuned Embeddings
Train your embedding model on domain-specific query-document pairs. The model learns that "MI" and "myocardial infarction" and "heart attack" should have similar embeddings in a medical context. Benchmarks show 5-10% accuracy improvement. A smaller fine-tuned model can outperform a larger generic one. But it requires training data (thousands of pairs), infrastructure, and ongoing maintenance. Only worth it for specialized domains where generic models underperform.
Combining Strategies: Four Production Stacks
In production, you don't pick one strategy — you stack them. Here are four combinations for different requirements.
The Fast and Good Stack
Context-aware chunking + multi-query RAG + optional re-ranking. Handles the vast majority of use cases with reasonable latency and cost.
The Highest Accuracy Stack
Context-aware chunking + contextual retrieval (at ingestion) + re-ranking (at query time). For when wrong answers have real consequences — medical, legal, financial. Higher ingestion cost (LLM calls per chunk), but Anthropic's benchmarks show up to 67% reduction in retrieval failures.
The Maximum Flexibility Stack
Agentic RAG with multiple tools — semantic search, multi-query, re-ranking, and full-document retrieval all available. The agent picks the right approach per query. Most adaptable, but hardest to debug.
The Research-Grade Stack
Highest accuracy stack + self-reflective RAG. Slowest and most expensive, but produces the best results for complex, multi-faceted queries. Use when latency is acceptable and accuracy is everything.
Cost vs. Quality
Low cost: Standard search, context-aware chunking, re-ranking. Medium cost: Multi-query, query expansion, agentic retrieval. High cost: Contextual retrieval (LLM per chunk), self-reflective RAG (multiple LLM calls per query), knowledge graphs (database maintenance), fine-tuned embeddings (training). Match the investment to the stakes.
Frequently Asked Questions
Which strategy should I start with?
Context-aware chunking as your ingestion default, then add re-ranking. Re-ranking is the single highest-impact query-time improvement — it adds precision without changing your ingestion pipeline. From there, add multi-query for better recall or contextual retrieval for better chunk quality, depending on where your system fails.
Can I use all 11 strategies at once?
Technically, yes. Practically, no. Each strategy adds latency, cost, or complexity. Stack strategically — identify your biggest failure mode, add the strategy that addresses it, measure the improvement, and repeat. The teams that build the best systems add complexity only where it's needed.
How do I evaluate whether a strategy is working?
Use the RAGAS framework — it measures faithfulness (does the answer match the context?), relevance (does the context match the query?), and correctness. But also test with real queries from real users. The gap between benchmark and real-world performance is often significant.
Is agentic RAG worth the complexity?
If your queries vary significantly in type and complexity — some need simple lookups, others need multi-step research — then yes. If most queries follow the same pattern, a fixed pipeline with re-ranking is simpler and more predictable.
Do I need knowledge graphs?
Only if your data is fundamentally about relationships between entities. Healthcare (patient-provider-treatment), finance (company-investor-deals), research (paper-author-concept). For most document-based RAG systems, vector search with re-ranking handles the job well.
Build It, Measure It, Improve It
RAG isn't just a technique — it's a shift in how we think about AI systems. Instead of cramming all knowledge into a model's weights, we're building systems that know how to find and use information. That's a more human approach to intelligence. You don't memorize everything. You build mental models of how things work, and when you need specifics, you look them up. RAG gives AI systems that same capability.
The 11 strategies I've covered across this series — from basic vector search to self-reflective RAG and knowledge graphs — represent the current state of the art. But the field is moving fast. Agentic RAG is evolving toward systems that actively reason about what information they need. Multi-modal RAG extends these concepts to images, audio, and video. And as embedding models improve, every strategy built on top of them gets better for free.
From a practical standpoint, here's my recommendation. Start simple. Get a basic pipeline working with context-aware chunking and standard vector search. See where it fails. Then add strategies — re-ranking for precision, multi-query for recall, contextual retrieval for accuracy — one at a time, measuring the impact of each.
The teams that build the best RAG systems aren't the ones that implement the most complex architecture on day one. They're the ones that start simple, measure rigorously, and add complexity only where it's needed.
The tools and strategies are here. Your data is waiting. The question isn't whether RAG works — it's how well you can make it work for your specific problem.
Build it, measure it, improve it. That's the path.
P.S. If you're starting fresh, begin with Part 1: What Is RAG and Why Your LLM Needs It, then Part 2: Embeddings, Vector Databases, and Chunking, and explore the companion repository for working implementations of all 11 strategies.
Read The Part 1
Read The Part 2
Don't miss out on future posts and exclusive content—subscribe to my free newsletter today.
Ready to connect or explore more? Head over to my LinkedIn profile